if (!requireNamespace("tidyverse", quietly = TRUE)) install.packages("tidyverse")
if (!requireNamespace("naniar", quietly = TRUE)) install.packages("naniar")3 Manejo de datos
3.1 Introduccion al Manejo de Datos
En el campo de la ciencia de datos, la efectividad de los resultados depende en gran medida de la gestión de los datos. R, como herramienta central, ofrece soluciones para enfrentar desafíos prácticos en conjuntos de datos reales. Nos adentraremos en la identificación y corrección de datos faltantes, valores atípicos e inconsistencias, aplicando técnicas precisas de R. Este enfoque, ejemplificado con casos concretos, nos permitirá abordar situaciones del mundo real y convertir datos complejos en conocimientos valiosos. Este trabajo explora cómo, a través de R, transformamos la incertidumbre en claridad y desciframos historias significativas a partir de datos desafiantes.
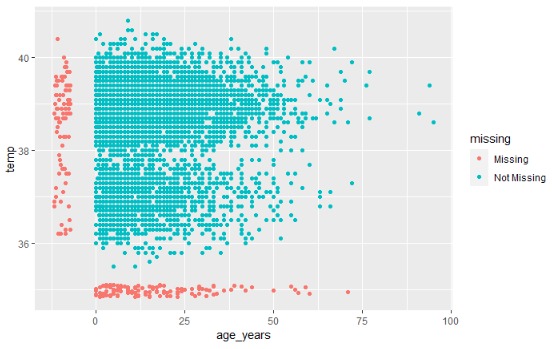
3.2 Identificación y Manejo de Datos Missing
3.2.1 ¿Qué Son los Datos Missing?
Los datos faltantes, también conocidos como datos ausentes, son valores que no están presentes en un conjunto de datos donde se espera encontrar información. Pueden originarse por diversas razones, desde errores en la recopilación de datos hasta las complejidades inherentes a los fenómenos que estamos investigando.
3.2.2 Importancia de los Datos Missing
La existencia de datos faltantes puede acarrear consecuencias significativas. Estos vacíos pueden distorsionar los resultados de nuestros análisis, afectar la validez de nuestras conclusiones y disminuir la efectividad de los modelos predictivos. Entender y abordar estas ausencias en nuestros datos es fundamental para asegurar la precisión y confiabilidad de nuestras interpretaciones.
3.2.3 Tipos de Datos Missing en R
En R, los datos faltantes son representados por el valor especial NA (Not Available). Este valor puede manifestarse de diferentes maneras, dependiendo del tipo de datos. A continuación se describen los tipos de datos missing más comunes:
3.2.3.1 A. NA Lógico
- Representación:
NA - Descripción: Utilizado en variables lógicas (
logical) para indicar que el valor es desconocido o no está disponible.
3.2.3.2 B. NA Numérico
- Representación:
NAoNaN(Not a Number) - Descripción: Aplicable a variables numéricas (
numeric) para indicar valores desconocidos o resultados indefinidos, como en operaciones matemáticas no definidas.
3.2.3.3 C. NA de Carácter
- Representación:
NA - Descripción: En variables de tipo carácter (
character), se utilizaNApara indicar datos faltantes o no disponibles.
3.2.3.4 D. NA de Factor
- Representación:
NA - Descripción: En variables de tipo factor (
factor),NAse utiliza para denotar categorías o niveles no especificados o desconocidos.
3.2.3.5 E. NA de Fecha y Hora
- Representación:
NA - Descripción: En variables de fecha y hora (
Date,POSIXct, etc.),NAindica fechas o momentos temporales no disponibles o desconocidos.
Estos tipos de datos missing permiten a los usuarios trabajar con datos ausentes en distintos contextos, facilitando su identificación y manejo en análisis de datos y estadísticas.
3.2.4 Abordamiento de Datos Missing - Estrategias para la Identificacion
3.2.4.1 Paquetes o Herramiente para abordar el tratamiento de estos datos
Nota: Se brindara diferentes metodos y alternativas para ese abordamiento
Verificacion e Installation de paquetes:
3.2.4.2 Carga de Paquetes:
# naniar: Paquete para visualizar patrones de datos missing
library(naniar)3.2.4.3 Importación de la Data
#Le asignaremos un nombre a nuestro link
url <- "https://raw.githubusercontent.com/korbinianheimerl/predictingMissingValues/main/train.csv"
#Leemos los datos y los cargamos en una variable datos
datos <- read.csv(url)
# Muestra la estructura de los datos importados
str(datos)'data.frame': 891 obs. of 12 variables:
$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
$ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
$ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen, Miss. Laina" "Futrelle, Mrs. Jacques Heath (Lily May Peel)" ...
$ Sex : chr "male" "female" "female" "female" ...
$ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
$ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
$ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ...
$ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
$ Cabin : chr "" "C85" "" "C123" ...
$ Embarked : chr "S" "C" "S" "S" ...# Muestra las primeras filas de los datos
head(datos) PassengerId Survived Pclass
1 1 0 3
2 2 1 1
3 3 1 3
4 4 1 1
5 5 0 3
6 6 0 3
Name Sex Age SibSp Parch
1 Braund, Mr. Owen Harris male 22 1 0
2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
3 Heikkinen, Miss. Laina female 26 0 0
4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
5 Allen, Mr. William Henry male 35 0 0
6 Moran, Mr. James male NA 0 0
Ticket Fare Cabin Embarked
1 A/5 21171 7.2500 S
2 PC 17599 71.2833 C85 C
3 STON/O2. 3101282 7.9250 S
4 113803 53.1000 C123 S
5 373450 8.0500 S
6 330877 8.4583 Q3.2.4.4 Vizualicacion de Patrones
Una de las funciones mas empleadas para la Vizualicacion de Patrones es la funcion naniar la cual utilizaremos para poder indetificar los datos missing
# Cargamos los paquetes
library(naniar)
library(ggplot2)
#Definir la Funcion para ver la proporcion de datos Missing
visualizar_datos_missing_naniar <- function(datos) {
miss_var_summary(datos) %>%
ggplot(aes(x = n_miss, y = pct_miss)) +
geom_point(aes(color = n_miss)) +
labs(title = "Patrones de Datos Missing",
x = "Número de Datos Missing",
y = "Proporción de Datos Missing") +
theme_minimal()
}
# Llamada a la función
visualizar_datos_missing_naniar(datos)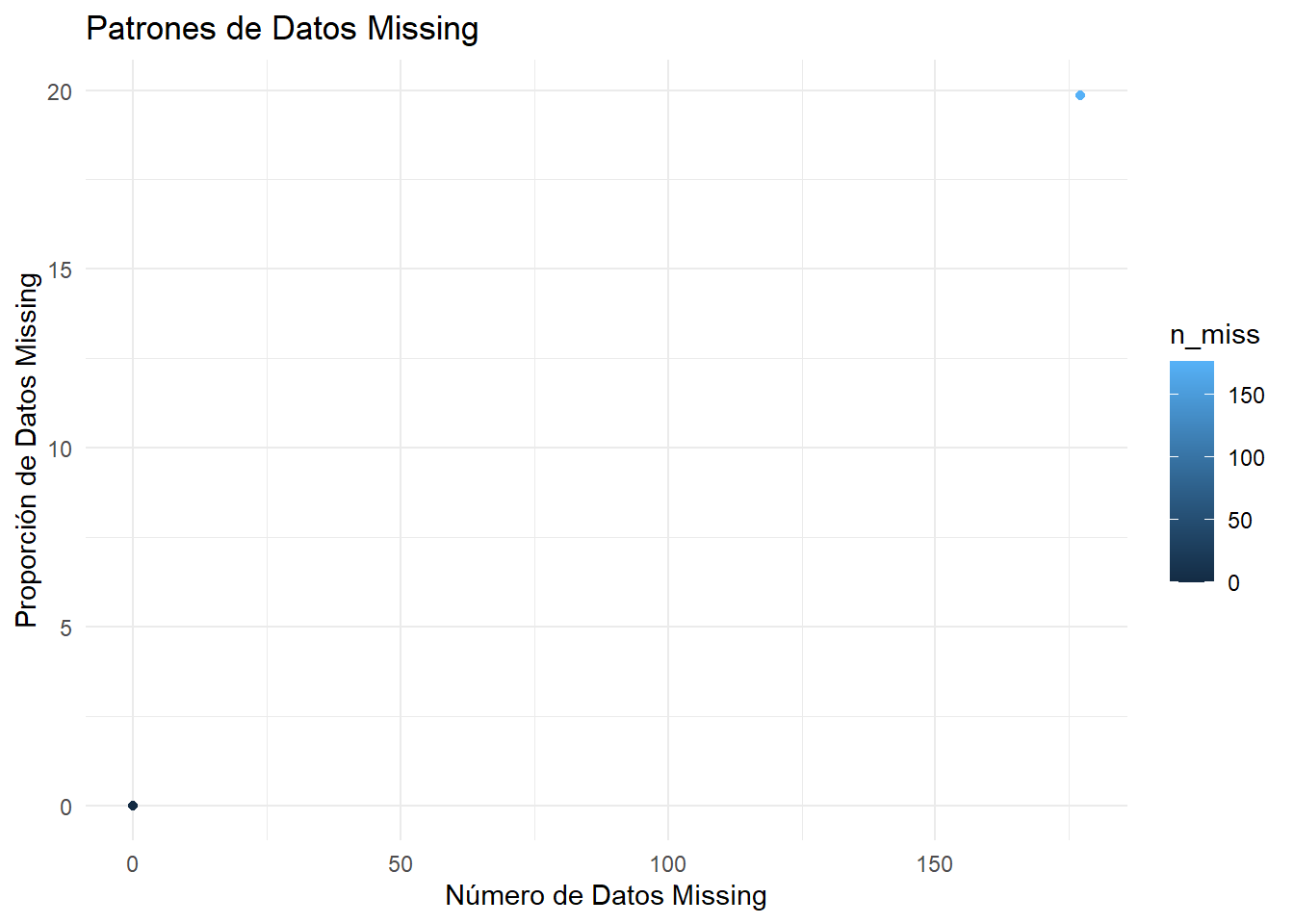
3.2.4.5 Resumenes Estadisticos
Nos permite tener una idea mas clara para poder interpretar la data en la cual estamos trabajando y las incosistencias que pueda presentar para ello utilizaremos el calculo de proporciones para los datos faltantes en cada variable de un conjunto de datos, representado por la matriz “datos”.
En primer lugar, se genera una matriz lógica utilizando la función “is.na(datos)”, donde cada entrada se evalúa como verdadera si el dato asociado es missing y falso en caso contrario.
Luego, la función “colMeans(…)” calcula la media de cada columna de esta matriz lógica, produciendo un vector que indica la proporción de datos faltantes por variable. El resultado se almacena en la variable “prop_missing”.
# Cálculo de la proporción de datos missing por variable
prop_missing <- colMeans(is.na(datos))
prop_missingPassengerId Survived Pclass Name Sex Age
0.0000000 0.0000000 0.0000000 0.0000000 0.0000000 0.1986532
SibSp Parch Ticket Fare Cabin Embarked
0.0000000 0.0000000 0.0000000 0.0000000 0.0000000 0.0000000 3.2.5 Estrategias para el Manejo y Analisis
3.2.5.1 Imputación
Existen varias técnicas de imputación, entre las cuales se incluyen:
Media o Mediana: Reemplazar los valores faltantes con la media o mediana de la variable. Es simple y efectiva, aunque puede no ser ideal para datos sesgados.
Regresión: Utilizar un modelo de regresión para predecir los valores faltantes basándose en otras variables observadas.
Vecinos más Cercanos (k-NN): Encontrar observaciones similares y utilizar sus valores para imputar los valores faltantes.
Reglas de Negocio: Utilizar conocimiento experto o reglas específicas del dominio para imputar valores.
3.2.5.2 Eliminación
La eliminación de datos faltantes es otra estrategia común para manejar valores ausentes en conjuntos de datos. En lugar de imputar o rellenar los valores faltantes, esta estrategia implica eliminar las observaciones que tienen al menos un valor faltante.
Existen dos enfoques principales:
Eliminación de Filas: Eliminar todas las filas que contienen al menos un valor faltante. Este enfoque simplifica el conjunto de datos pero puede resultar en la pérdida de información valiosa.
Eliminación de Columnas: Eliminar las columnas que tienen valores faltantes. Este enfoque se utiliza cuando ciertas variables son mayormente incompletas y no son críticas para el análisis.
Es importante considerar estos métodos con cautela, ya que la eliminación puede introducir sesgos y reducir la representatividad del conjunto de datos.
3.2.5.3 Reemplazando valores faltantes por el Metodo de Imputacion de la Media o Mediana:
names(datos) [1] "PassengerId" "Survived" "Pclass" "Name" "Sex"
[6] "Age" "SibSp" "Parch" "Ticket" "Fare"
[11] "Cabin" "Embarked" Asignar una función para hallar la moda
moda = getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}# Ordenamiento de data (Asignar NA a las celdas vacias )
datos <- read.csv(url("https://raw.githubusercontent.com/korbinianheimerl/predictingMissingValues/main/train.csv"), header = TRUE, sep = ',', na.strings = '')#Identificar datos Faltantes
sum(is.na(datos))[1] 866#Datos Faltantes por columnas
sum(is.na(datos$PassengerId))[1] 0sum(is.na(datos$Pclass))[1] 0sum(is.na(datos$Name))[1] 0sum(is.na(datos$Sex))[1] 0sum(is.na(datos$Age))[1] 177sum(is.na(datos$Parch))[1] 0sum(is.na(datos$Ticket))[1] 0sum(is.na(datos$Fare))[1] 0sum(is.na(datos$Cabin)) [1] 687sum(is.na(datos$Embarked))[1] 23.2.5.3.1 Primera opcion
datoslimpios = na.omit(datos)
head(datoslimpios) PassengerId Survived Pclass
2 2 1 1
4 4 1 1
7 7 0 1
11 11 1 3
12 12 1 1
22 22 1 2
Name Sex Age SibSp Parch
2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
7 McCarthy, Mr. Timothy J male 54 0 0
11 Sandstrom, Miss. Marguerite Rut female 4 1 1
12 Bonnell, Miss. Elizabeth female 58 0 0
22 Beesley, Mr. Lawrence male 34 0 0
Ticket Fare Cabin Embarked
2 PC 17599 71.2833 C85 C
4 113803 53.1000 C123 S
7 17463 51.8625 E46 S
11 PP 9549 16.7000 G6 S
12 113783 26.5500 C103 S
22 248698 13.0000 D56 S3.2.5.3.2 Segunda opcion
# 1.Asignar la media de la edad a los espacios en blancos
mediaage = round(mean(datoslimpios$Age))
datos$Age[is.na(datos$Age)] = mediaage
print(mediaage)[1] 36# 2.Asignar la moda de la Embarked a los espacios en blancos
modaembarked = moda(datoslimpios$Embarked)
datos$Embarked[is.na(datos$Embarked)] = modaembarked
print(modaembarked)[1] "S"# 3.Asignar la moda a los espacios en blancos de la columna de Cabin
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionlibrary(tidyr)
# Calcula la moda de la columna "Cabin"
moda_cabina <- datoslimpios %>%
filter(!is.na(Cabin)) %>%
count(Cabin) %>%
slice(which.max(n)) %>%
pull(Cabin)
# Asigna la moda a las filas con NA en la columna "Cabin"
datoslimpios$Cabin[is.na(datoslimpios$Cabin)] <- moda_cabina
print(moda_cabina)[1] "B96 B98"3.3 Identificación y manejo de datos outlier e inconsistentes.
3.3.1 Introducción
Este documento aborda estrategias en R para la identificación y gestión de valores atípicos (outliers) e inconsistencias en conjuntos de datos, asegurando la fiabilidad de los resultados.
3.3.2 Identificación de Outliers
- Visualización Gráfica: Boxplots, gráficos de dispersión y histogramas.
#Conocer mis intervalos del tipo de dato el cual voy a trabajar
str(datos$Age) num [1:891] 22 38 26 35 35 36 54 2 27 14 ...# Obtener el histograma de la columna "Age"
hist(datos$Age, main = "Histograma de Edades", xlab = "Edad", ylab = "Frecuencia")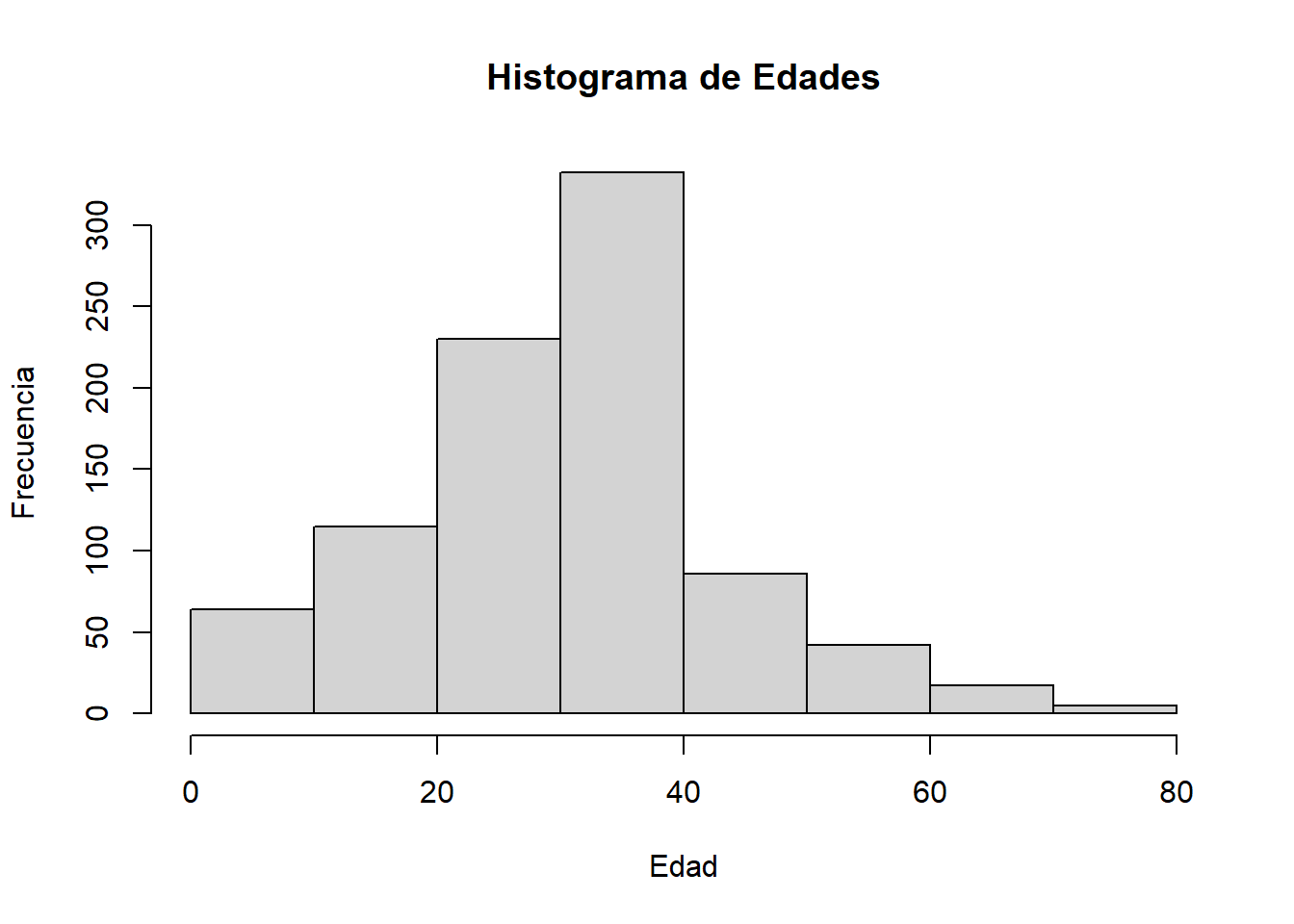
# Hacer un gráfico de caja y bigotes para la columna "Age"
boxplot(datos$Age, horizontal = TRUE, main = "Diagrama de Cajas - Edad", xlab = "Edad")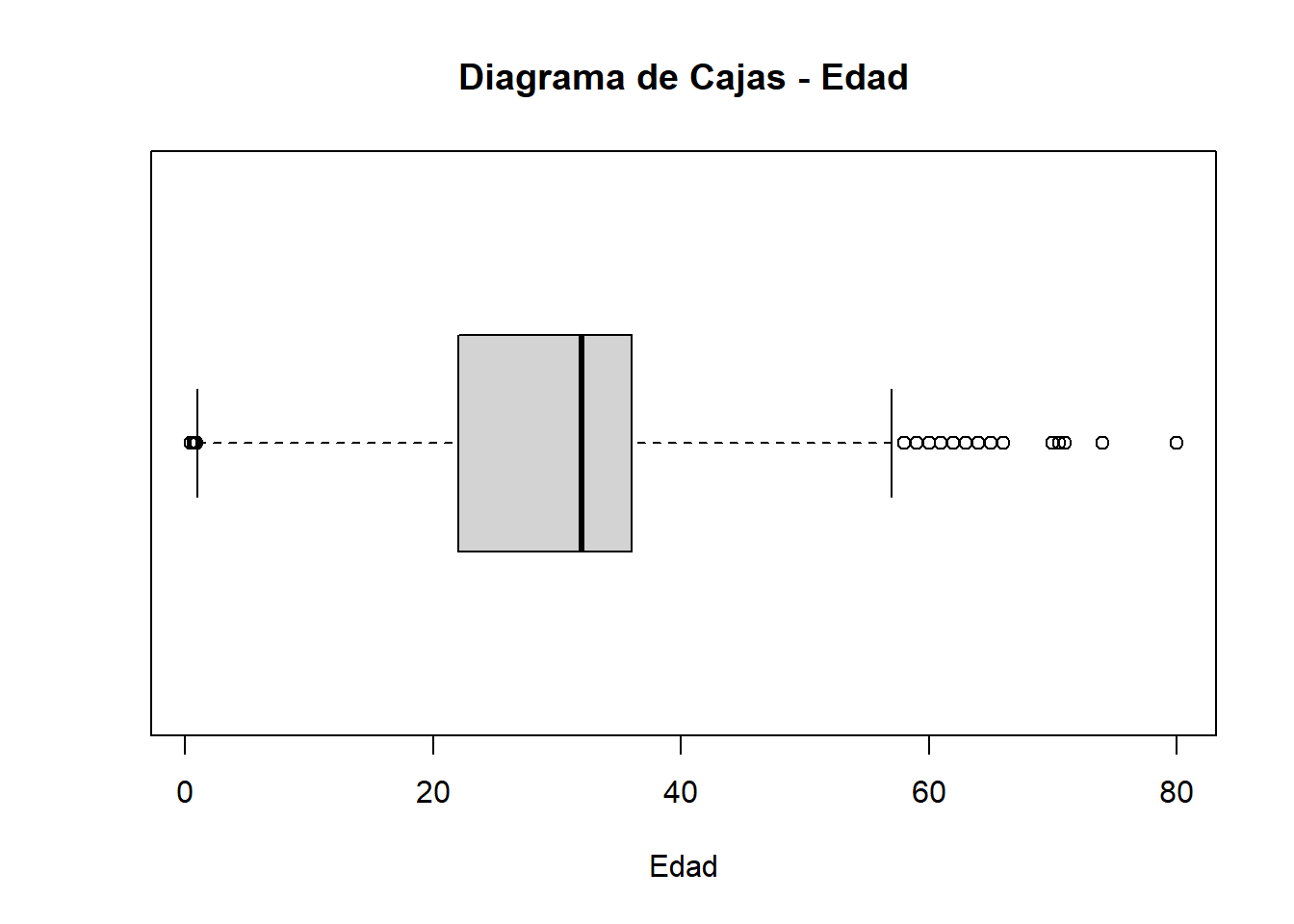
OBS: Se puede Observar datos atipicos en el diagrama de caja lo cual es un indicador para poder realizar una ajuste.
3.3.3 Presentación de datos Outliers
boxplot.stats(datos$Age)$stats
[1] 1 22 32 36 57
$n
[1] 891
$conf
[1] 31.25895 32.74105
$out
[1] 58.00 66.00 65.00 0.83 59.00 71.00 70.50 61.00 58.00 59.00 62.00 58.00
[13] 63.00 65.00 0.92 61.00 60.00 64.00 65.00 0.75 63.00 58.00 71.00 64.00
[25] 62.00 62.00 60.00 61.00 80.00 0.75 58.00 70.00 60.00 60.00 70.00 0.67
[37] 0.42 62.00 0.83 74.003.3.4 Manejo de Outliers
- Transformación de Datos: Aplicación de transformaciones para reducir la influencia de outliers.
# Obtener los datos que no son Outliers
# Filtra las filas donde la edad es mayor a 5 y menor a 60, y selecciona la columna "Age"
edad_sin_out <- datos[datos$Age > 5 & datos$Age < 60, "Age"]
# Imprime la columna "Age" filtrada
print(edad_sin_out) [1] 22.0 38.0 26.0 35.0 35.0 36.0 54.0 27.0 14.0 58.0 20.0 39.0 14.0 55.0 36.0
[16] 31.0 36.0 35.0 34.0 15.0 28.0 8.0 38.0 36.0 19.0 36.0 36.0 40.0 36.0 36.0
[31] 28.0 42.0 36.0 21.0 18.0 14.0 40.0 27.0 36.0 19.0 36.0 36.0 36.0 36.0 18.0
[46] 7.0 21.0 49.0 29.0 36.0 21.0 28.5 11.0 22.0 38.0 45.0 36.0 36.0 29.0 19.0
[61] 17.0 26.0 32.0 16.0 21.0 26.0 32.0 25.0 36.0 36.0 30.0 22.0 29.0 36.0 28.0
[76] 17.0 33.0 16.0 36.0 23.0 24.0 29.0 20.0 46.0 26.0 59.0 36.0 23.0 34.0 34.0
[91] 28.0 36.0 21.0 33.0 37.0 28.0 21.0 36.0 38.0 36.0 47.0 14.5 22.0 20.0 17.0
[106] 21.0 29.0 24.0 21.0 36.0 32.5 32.5 54.0 12.0 36.0 24.0 36.0 45.0 33.0 20.0
[121] 47.0 29.0 25.0 23.0 19.0 37.0 16.0 24.0 36.0 22.0 24.0 19.0 18.0 19.0 27.0
[136] 9.0 36.5 42.0 51.0 22.0 55.5 40.5 36.0 51.0 16.0 30.0 36.0 36.0 44.0 40.0
[151] 26.0 17.0 9.0 36.0 45.0 36.0 28.0 21.0 56.0 18.0 36.0 50.0 30.0 36.0 36.0
[166] 36.0 9.0 36.0 36.0 45.0 40.0 36.0 32.0 19.0 19.0 44.0 58.0 36.0 42.0 36.0
[181] 24.0 28.0 36.0 34.0 45.5 18.0 32.0 26.0 16.0 40.0 24.0 35.0 22.0 30.0 36.0
[196] 31.0 27.0 42.0 32.0 30.0 16.0 27.0 51.0 36.0 38.0 22.0 19.0 20.5 18.0 36.0
[211] 35.0 29.0 59.0 24.0 36.0 44.0 8.0 19.0 33.0 36.0 36.0 29.0 22.0 30.0 44.0
[226] 25.0 24.0 37.0 54.0 36.0 29.0 30.0 41.0 29.0 36.0 30.0 35.0 50.0 36.0 52.0
[241] 40.0 36.0 36.0 16.0 25.0 58.0 35.0 36.0 25.0 41.0 37.0 36.0 45.0 36.0 7.0
[256] 35.0 28.0 16.0 19.0 36.0 33.0 30.0 22.0 42.0 22.0 26.0 19.0 36.0 24.0 24.0
[271] 36.0 23.5 36.0 50.0 36.0 36.0 19.0 36.0 36.0 36.0 17.0 30.0 30.0 24.0 18.0
[286] 26.0 28.0 43.0 26.0 24.0 54.0 31.0 40.0 22.0 27.0 30.0 22.0 36.0 36.0 36.0
[301] 31.0 16.0 36.0 45.5 38.0 16.0 36.0 36.0 29.0 41.0 45.0 45.0 24.0 28.0 25.0
[316] 36.0 24.0 40.0 36.0 42.0 23.0 36.0 15.0 25.0 36.0 28.0 22.0 38.0 36.0 36.0
[331] 40.0 29.0 45.0 35.0 36.0 30.0 36.0 36.0 24.0 25.0 18.0 19.0 22.0 36.0 22.0
[346] 27.0 20.0 19.0 42.0 32.0 35.0 36.0 18.0 36.0 36.0 17.0 36.0 21.0 28.0 23.0
[361] 24.0 22.0 31.0 46.0 23.0 28.0 39.0 26.0 21.0 28.0 20.0 34.0 51.0 21.0 36.0
[376] 36.0 36.0 33.0 36.0 44.0 36.0 34.0 18.0 30.0 10.0 36.0 21.0 29.0 28.0 18.0
[391] 36.0 28.0 19.0 36.0 32.0 28.0 36.0 42.0 17.0 50.0 14.0 21.0 24.0 31.0 45.0
[406] 20.0 25.0 28.0 36.0 13.0 34.0 52.0 36.0 36.0 30.0 49.0 36.0 29.0 36.0 50.0
[421] 36.0 48.0 34.0 47.0 48.0 36.0 38.0 36.0 56.0 36.0 36.0 38.0 33.0 23.0 22.0
[436] 36.0 34.0 29.0 22.0 9.0 36.0 50.0 25.0 36.0 35.0 58.0 30.0 9.0 36.0 21.0
[451] 55.0 21.0 36.0 54.0 36.0 25.0 24.0 17.0 21.0 36.0 37.0 16.0 18.0 33.0 36.0
[466] 28.0 26.0 29.0 36.0 36.0 54.0 24.0 47.0 34.0 36.0 36.0 32.0 30.0 22.0 36.0
[481] 44.0 36.0 40.5 50.0 36.0 39.0 23.0 36.0 17.0 36.0 30.0 7.0 45.0 30.0 36.0
[496] 22.0 36.0 9.0 11.0 32.0 50.0 19.0 36.0 33.0 8.0 17.0 27.0 36.0 22.0 22.0
[511] 48.0 36.0 39.0 36.0 36.0 40.0 28.0 36.0 36.0 24.0 19.0 29.0 36.0 32.0 53.0
[526] 36.0 36.0 16.0 19.0 34.0 39.0 36.0 32.0 25.0 39.0 54.0 36.0 36.0 18.0 47.0
[541] 22.0 36.0 35.0 52.0 47.0 36.0 37.0 36.0 36.0 49.0 36.0 49.0 24.0 36.0 36.0
[556] 44.0 35.0 36.0 30.0 27.0 22.0 40.0 39.0 36.0 36.0 36.0 35.0 24.0 34.0 26.0
[571] 26.0 27.0 42.0 20.0 21.0 21.0 57.0 21.0 26.0 36.0 51.0 32.0 36.0 9.0 28.0
[586] 32.0 31.0 41.0 36.0 20.0 24.0 36.0 48.0 19.0 56.0 36.0 23.0 36.0 18.0 21.0
[601] 36.0 18.0 24.0 36.0 32.0 23.0 58.0 50.0 40.0 47.0 36.0 20.0 32.0 25.0 36.0
[616] 43.0 36.0 40.0 31.0 31.0 36.0 18.0 24.5 18.0 43.0 36.0 36.0 27.0 20.0 14.0
[631] 25.0 14.0 19.0 18.0 15.0 31.0 36.0 25.0 52.0 44.0 36.0 49.0 42.0 18.0 35.0
[646] 18.0 25.0 26.0 39.0 45.0 42.0 22.0 36.0 24.0 36.0 48.0 29.0 52.0 19.0 38.0
[661] 27.0 36.0 33.0 6.0 17.0 34.0 50.0 27.0 20.0 30.0 36.0 25.0 25.0 29.0 11.0
[676] 36.0 23.0 23.0 28.5 48.0 35.0 36.0 36.0 36.0 36.0 21.0 24.0 31.0 16.0 30.0
[691] 19.0 31.0 6.0 33.0 23.0 48.0 28.0 18.0 34.0 33.0 36.0 41.0 20.0 36.0 16.0
[706] 51.0 36.0 30.5 36.0 32.0 24.0 48.0 57.0 36.0 54.0 18.0 36.0 36.0 43.0 13.0
[721] 17.0 29.0 36.0 25.0 25.0 18.0 8.0 46.0 36.0 16.0 36.0 36.0 25.0 39.0 49.0
[736] 31.0 30.0 30.0 34.0 31.0 11.0 27.0 31.0 39.0 18.0 39.0 33.0 26.0 39.0 35.0
[751] 6.0 30.5 36.0 23.0 31.0 43.0 10.0 52.0 27.0 38.0 27.0 36.0 36.0 36.0 15.0
[766] 36.0 23.0 18.0 39.0 21.0 36.0 32.0 36.0 20.0 16.0 30.0 34.5 17.0 42.0 36.0
[781] 35.0 28.0 36.0 9.0 16.0 44.0 18.0 45.0 51.0 24.0 36.0 41.0 21.0 48.0 36.0
[796] 24.0 42.0 27.0 31.0 36.0 26.0 47.0 33.0 47.0 28.0 15.0 20.0 19.0 36.0 56.0
[811] 25.0 33.0 22.0 28.0 25.0 39.0 27.0 19.0 36.0 26.0 32.0# Nuevo diagrama de cajas y bigotes con la columna "Age" filtrada
boxplot(edad_sin_out, horizontal = TRUE, main = "Diagrama de Cajas - Edad sin Outliers", xlab = "Edad")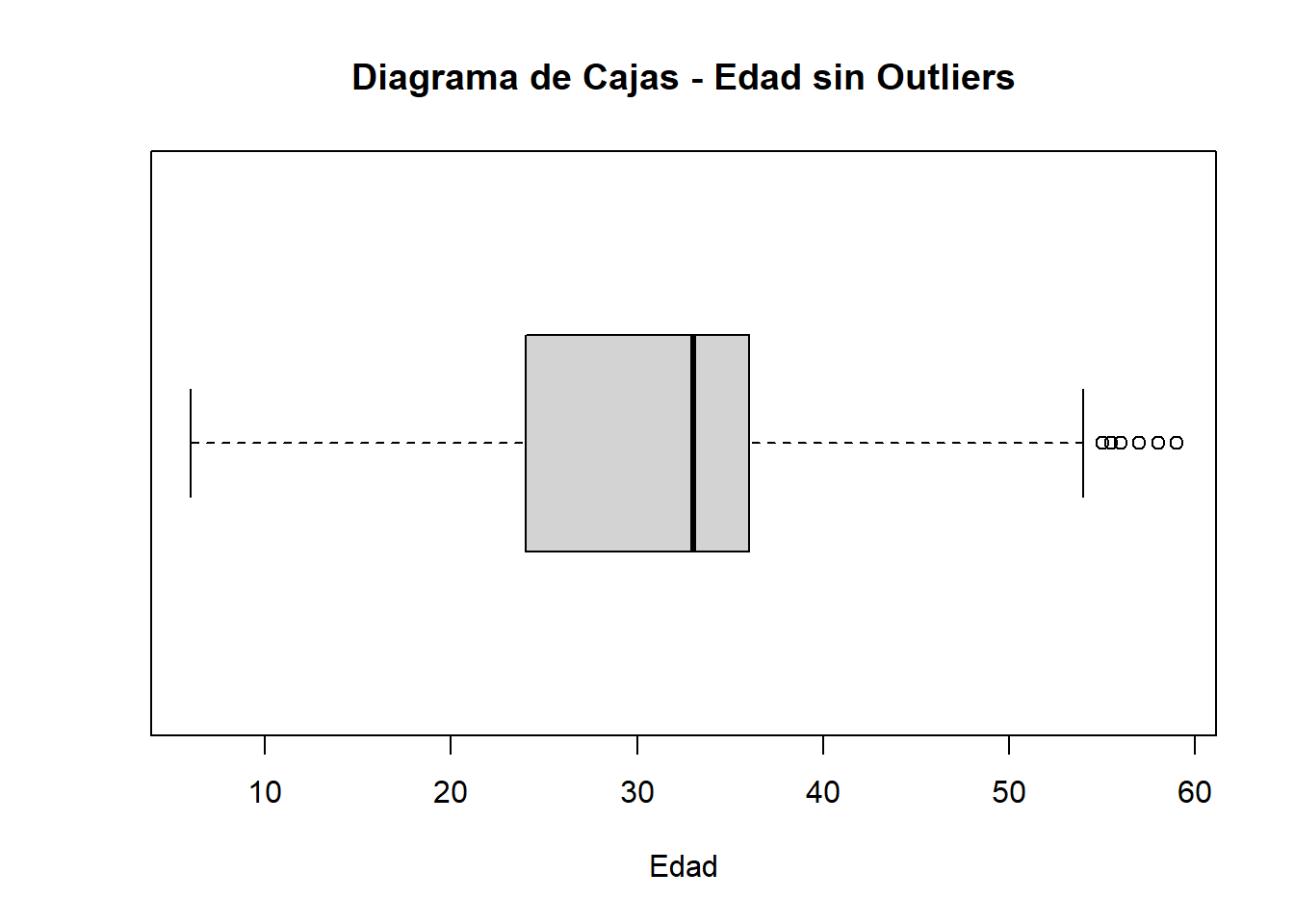
3.4 Limpieza de datos y preparación de datos.
3.4.1 Trabajaremos con la misma data utilizada anteriormente
#Le asignaremos un nombre a nuestro link
url <- "https://raw.githubusercontent.com/korbinianheimerl/predictingMissingValues/main/train.csv"
#Leemos los datos y los cargamos en una variable datos
datos <- read.csv(url)
# Muestra la estructura de los datos importados
str(datos)'data.frame': 891 obs. of 12 variables:
$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
$ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
$ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen, Miss. Laina" "Futrelle, Mrs. Jacques Heath (Lily May Peel)" ...
$ Sex : chr "male" "female" "female" "female" ...
$ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
$ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
$ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ...
$ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
$ Cabin : chr "" "C85" "" "C123" ...
$ Embarked : chr "S" "C" "S" "S" ...# Muestra las primeras filas de los datos
head(datos) PassengerId Survived Pclass
1 1 0 3
2 2 1 1
3 3 1 3
4 4 1 1
5 5 0 3
6 6 0 3
Name Sex Age SibSp Parch
1 Braund, Mr. Owen Harris male 22 1 0
2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
3 Heikkinen, Miss. Laina female 26 0 0
4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
5 Allen, Mr. William Henry male 35 0 0
6 Moran, Mr. James male NA 0 0
Ticket Fare Cabin Embarked
1 A/5 21171 7.2500 S
2 PC 17599 71.2833 C85 C
3 STON/O2. 3101282 7.9250 S
4 113803 53.1000 C123 S
5 373450 8.0500 S
6 330877 8.4583 Q1.Examinar el nuestra data buscando valores faltantes y Outliers
1.1 Buscando Valores Faltantes
#Datos Faltantes por columnas
sum(is.na(datos$PassengerId))[1] 0sum(is.na(datos$Pclass))[1] 0sum(is.na(datos$Name))[1] 0sum(is.na(datos$Sex))[1] 0sum(is.na(datos$Age))[1] 177sum(is.na(datos$Parch))[1] 0sum(is.na(datos$Ticket))[1] 0sum(is.na(datos$Fare))[1] 0sum(is.na(datos$Cabin)) [1] 0sum(is.na(datos$Embarked))[1] 0Se observa que hay tres categorias que nos porporcionan celdas vacias entonces iremos tratando estos datos:
1.2 Encontrar medidas estadisticas para poder reemplazarlos en nuestra data a ello le denominamos “tecnica de imputacion por la media o moda” entonces:
Para ello limpiamos nuestros datos
datoslimpios = na.omit(datos)
# mostramos los primeros datos
head(datoslimpios) PassengerId Survived Pclass
1 1 0 3
2 2 1 1
3 3 1 3
4 4 1 1
5 5 0 3
7 7 0 1
Name Sex Age SibSp Parch
1 Braund, Mr. Owen Harris male 22 1 0
2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
3 Heikkinen, Miss. Laina female 26 0 0
4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
5 Allen, Mr. William Henry male 35 0 0
7 McCarthy, Mr. Timothy J male 54 0 0
Ticket Fare Cabin Embarked
1 A/5 21171 7.2500 S
2 PC 17599 71.2833 C85 C
3 STON/O2. 3101282 7.9250 S
4 113803 53.1000 C123 S
5 373450 8.0500 S
7 17463 51.8625 E46 S#utilizar la funcion para hallar estos estadisticos
moda = getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}# 1.Asignar la media de la edad a los espacios en blancos
mediaage = round(mean(datoslimpios$Age))
datos$Age[is.na(datos$Age)] = mediaage
print(mediaage)[1] 30# 2.Asignar la moda de la Embarked a los espacios en blancos
modaembarked = moda(datoslimpios$Embarked)
datos$Embarked[is.na(datos$Embarked)] = modaembarked
print(modaembarked)[1] "S"# Calcula la moda de la columna "Cabin"
library(dplyr)
moda_cabina <- datoslimpios %>%
filter(!is.na(Cabin)) %>%
count(Cabin) %>%
slice(which.max(n)) %>%
pull(Cabin)
# Asigna "B96 B98" a las celdas vacías en la columna "Cabin"
set.seed(123) # Establecer semilla para reproducibilidad
cabin_moda_aleatoria <- sample(c("B96 B98", datos$Cabin[!is.na(datos$Cabin)], replace = TRUE))
# Asigna los valores aleatorios a las celdas vacías en "Cabin"
datos$Cabin[is.na(datos$Cabin)] <- cabin_moda_aleatoria
# Asigna la moda a las celdas vacías en la columna "Cabin"
datoslimpios$Cabin[is.na(datoslimpios$Cabin)] <- moda_cabina
print(moda_cabina)[1] ""Datos sin Valores Faltantes
head(datos) PassengerId Survived Pclass
1 1 0 3
2 2 1 1
3 3 1 3
4 4 1 1
5 5 0 3
6 6 0 3
Name Sex Age SibSp Parch
1 Braund, Mr. Owen Harris male 22 1 0
2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
3 Heikkinen, Miss. Laina female 26 0 0
4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
5 Allen, Mr. William Henry male 35 0 0
6 Moran, Mr. James male 30 0 0
Ticket Fare Cabin Embarked
1 A/5 21171 7.2500 S
2 PC 17599 71.2833 C85 C
3 STON/O2. 3101282 7.9250 S
4 113803 53.1000 C123 S
5 373450 8.0500 S
6 330877 8.4583 QVerificacion de que no exista algun dato faltante:
sum(is.na(datos))[1] 0Verificacion exitosa
2. Buscando Valores Atipicos para ello utilizaremos el diagrama de cajas y bigotes
2.1 Conocer el intervalo de mis datos:
Nota: En este caso trabajaremos con la columna de las edades ya que este tipo de variable puede presenter datos atipicos
#Conocer mis intervalos del tipo de dato el cual voy a trabajar
str(datos$Age) num [1:891] 22 38 26 35 35 30 54 2 27 14 ...# Obtener el histograma de la columna "Age"
hist(datos$Age, main = "Histograma de Edades", xlab = "Edad", ylab = "Frecuencia")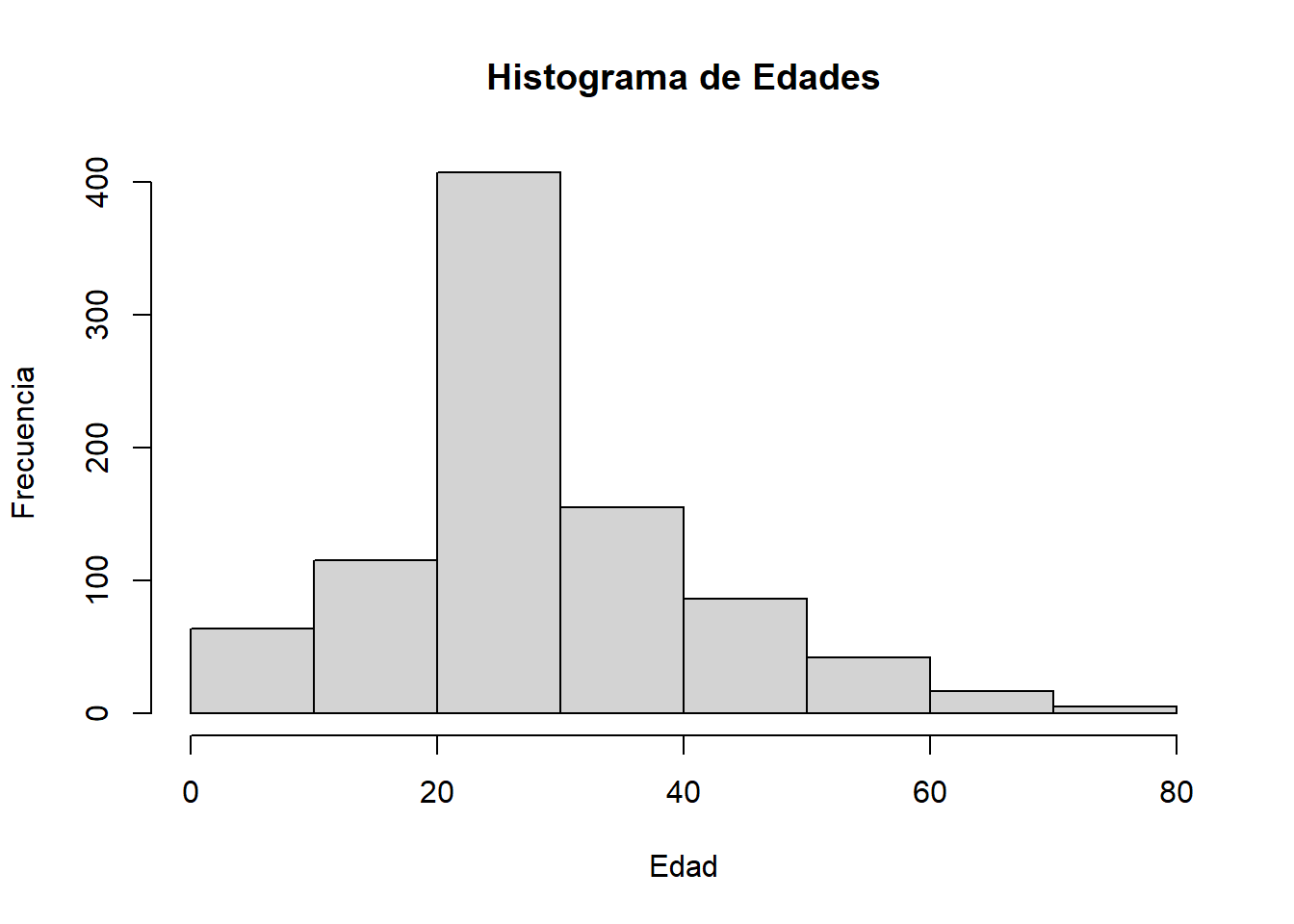
# Hacer un gráfico de caja y bigotes para la columna "Age"
boxplot(datos$Age, horizontal = TRUE, main = "Diagrama de Cajas - Edad", xlab = "Edad")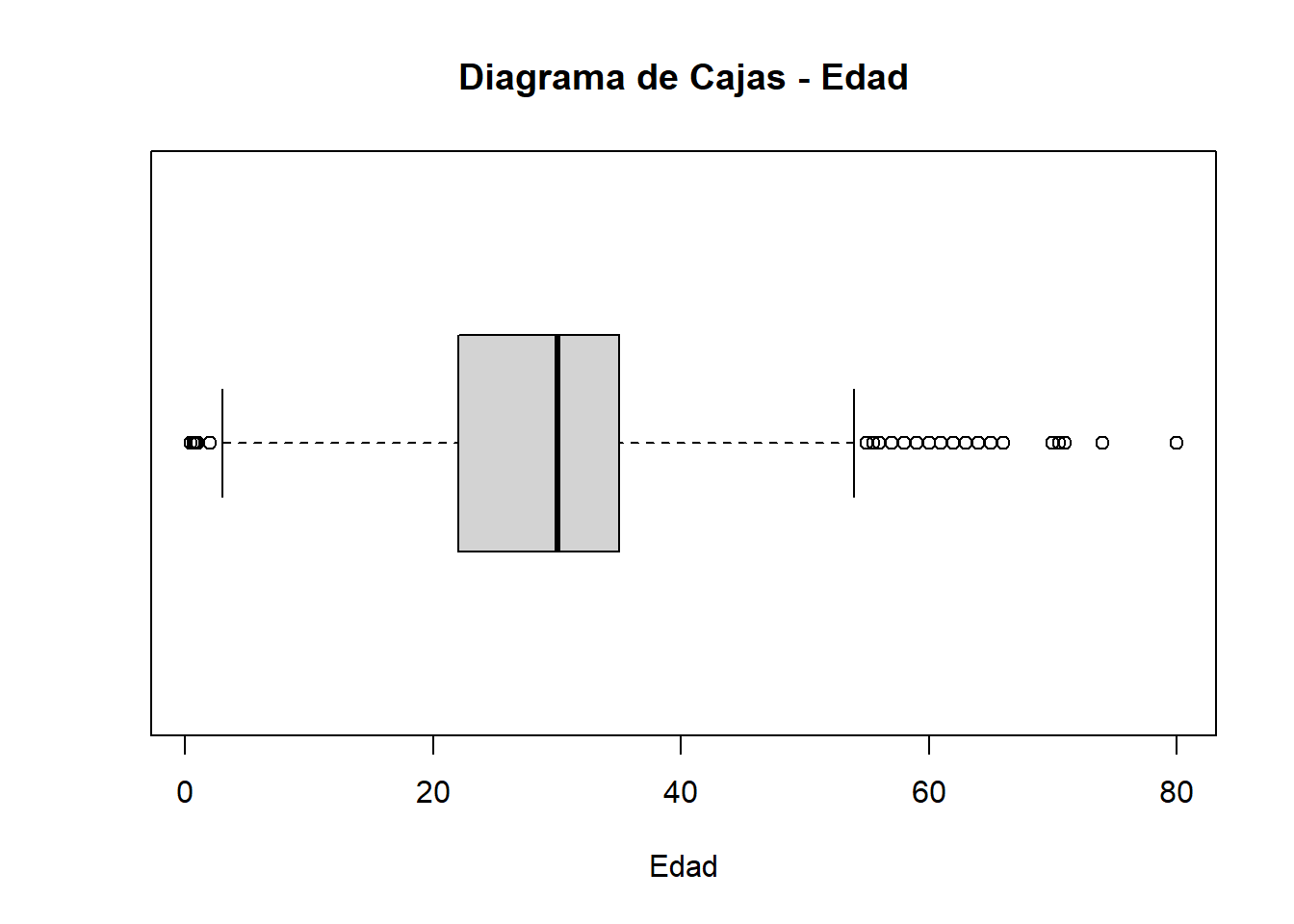
boxplot.stats(datos$Age)$stats
[1] 3 22 30 35 54
$n
[1] 891
$conf
[1] 29.31188 30.68812
$out
[1] 2.00 58.00 55.00 2.00 66.00 65.00 0.83 59.00 71.00 70.50 2.00 55.50
[13] 1.00 61.00 1.00 56.00 1.00 58.00 2.00 59.00 62.00 58.00 63.00 65.00
[25] 2.00 0.92 61.00 2.00 60.00 1.00 1.00 64.00 65.00 56.00 0.75 2.00
[37] 63.00 58.00 55.00 71.00 2.00 64.00 62.00 62.00 60.00 61.00 57.00 80.00
[49] 2.00 0.75 56.00 58.00 70.00 60.00 60.00 70.00 0.67 57.00 1.00 0.42
[61] 2.00 1.00 62.00 0.83 74.00 56.00# Obtener los datos que no son Outliers
# Filtra las filas donde la edad es mayor a 5 y menor a 60, y selecciona la columna "Age"
edad_sin_out <- datos[datos$Age > 5 & datos$Age < 60, "Age"]
# Imprime la columna "Age" filtrada
print(edad_sin_out) [1] 22.0 38.0 26.0 35.0 35.0 30.0 54.0 27.0 14.0 58.0 20.0 39.0 14.0 55.0 30.0
[16] 31.0 30.0 35.0 34.0 15.0 28.0 8.0 38.0 30.0 19.0 30.0 30.0 40.0 30.0 30.0
[31] 28.0 42.0 30.0 21.0 18.0 14.0 40.0 27.0 30.0 19.0 30.0 30.0 30.0 30.0 18.0
[46] 7.0 21.0 49.0 29.0 30.0 21.0 28.5 11.0 22.0 38.0 45.0 30.0 30.0 29.0 19.0
[61] 17.0 26.0 32.0 16.0 21.0 26.0 32.0 25.0 30.0 30.0 30.0 22.0 29.0 30.0 28.0
[76] 17.0 33.0 16.0 30.0 23.0 24.0 29.0 20.0 46.0 26.0 59.0 30.0 23.0 34.0 34.0
[91] 28.0 30.0 21.0 33.0 37.0 28.0 21.0 30.0 38.0 30.0 47.0 14.5 22.0 20.0 17.0
[106] 21.0 29.0 24.0 21.0 30.0 32.5 32.5 54.0 12.0 30.0 24.0 30.0 45.0 33.0 20.0
[121] 47.0 29.0 25.0 23.0 19.0 37.0 16.0 24.0 30.0 22.0 24.0 19.0 18.0 19.0 27.0
[136] 9.0 36.5 42.0 51.0 22.0 55.5 40.5 30.0 51.0 16.0 30.0 30.0 30.0 44.0 40.0
[151] 26.0 17.0 9.0 30.0 45.0 30.0 28.0 21.0 56.0 18.0 30.0 50.0 30.0 36.0 30.0
[166] 30.0 9.0 30.0 30.0 45.0 40.0 36.0 32.0 19.0 19.0 44.0 58.0 30.0 42.0 30.0
[181] 24.0 28.0 30.0 34.0 45.5 18.0 32.0 26.0 16.0 40.0 24.0 35.0 22.0 30.0 30.0
[196] 31.0 27.0 42.0 32.0 30.0 16.0 27.0 51.0 30.0 38.0 22.0 19.0 20.5 18.0 30.0
[211] 35.0 29.0 59.0 24.0 30.0 44.0 8.0 19.0 33.0 30.0 30.0 29.0 22.0 30.0 44.0
[226] 25.0 24.0 37.0 54.0 30.0 29.0 30.0 41.0 29.0 30.0 30.0 35.0 50.0 30.0 52.0
[241] 40.0 30.0 36.0 16.0 25.0 58.0 35.0 30.0 25.0 41.0 37.0 30.0 45.0 30.0 7.0
[256] 35.0 28.0 16.0 19.0 30.0 33.0 30.0 22.0 42.0 22.0 26.0 19.0 36.0 24.0 24.0
[271] 30.0 23.5 30.0 50.0 30.0 30.0 19.0 30.0 30.0 30.0 17.0 30.0 30.0 24.0 18.0
[286] 26.0 28.0 43.0 26.0 24.0 54.0 31.0 40.0 22.0 27.0 30.0 22.0 30.0 36.0 36.0
[301] 31.0 16.0 30.0 45.5 38.0 16.0 30.0 30.0 29.0 41.0 45.0 45.0 24.0 28.0 25.0
[316] 36.0 24.0 40.0 30.0 42.0 23.0 30.0 15.0 25.0 30.0 28.0 22.0 38.0 30.0 30.0
[331] 40.0 29.0 45.0 35.0 30.0 30.0 30.0 30.0 24.0 25.0 18.0 19.0 22.0 30.0 22.0
[346] 27.0 20.0 19.0 42.0 32.0 35.0 30.0 18.0 36.0 30.0 17.0 36.0 21.0 28.0 23.0
[361] 24.0 22.0 31.0 46.0 23.0 28.0 39.0 26.0 21.0 28.0 20.0 34.0 51.0 21.0 30.0
[376] 30.0 30.0 33.0 30.0 44.0 30.0 34.0 18.0 30.0 10.0 30.0 21.0 29.0 28.0 18.0
[391] 30.0 28.0 19.0 30.0 32.0 28.0 30.0 42.0 17.0 50.0 14.0 21.0 24.0 31.0 45.0
[406] 20.0 25.0 28.0 30.0 13.0 34.0 52.0 36.0 30.0 30.0 49.0 30.0 29.0 30.0 50.0
[421] 30.0 48.0 34.0 47.0 48.0 30.0 38.0 30.0 56.0 30.0 30.0 38.0 33.0 23.0 22.0
[436] 30.0 34.0 29.0 22.0 9.0 30.0 50.0 25.0 30.0 35.0 58.0 30.0 9.0 30.0 21.0
[451] 55.0 21.0 30.0 54.0 30.0 25.0 24.0 17.0 21.0 30.0 37.0 16.0 18.0 33.0 30.0
[466] 28.0 26.0 29.0 30.0 36.0 54.0 24.0 47.0 34.0 30.0 36.0 32.0 30.0 22.0 30.0
[481] 44.0 30.0 40.5 50.0 30.0 39.0 23.0 30.0 17.0 30.0 30.0 7.0 45.0 30.0 30.0
[496] 22.0 36.0 9.0 11.0 32.0 50.0 19.0 30.0 33.0 8.0 17.0 27.0 30.0 22.0 22.0
[511] 48.0 30.0 39.0 36.0 30.0 40.0 28.0 30.0 30.0 24.0 19.0 29.0 30.0 32.0 53.0
[526] 36.0 30.0 16.0 19.0 34.0 39.0 30.0 32.0 25.0 39.0 54.0 36.0 30.0 18.0 47.0
[541] 22.0 30.0 35.0 52.0 47.0 30.0 37.0 36.0 30.0 49.0 30.0 49.0 24.0 30.0 30.0
[556] 44.0 35.0 36.0 30.0 27.0 22.0 40.0 39.0 30.0 30.0 30.0 35.0 24.0 34.0 26.0
[571] 26.0 27.0 42.0 20.0 21.0 21.0 57.0 21.0 26.0 30.0 51.0 32.0 30.0 9.0 28.0
[586] 32.0 31.0 41.0 30.0 20.0 24.0 30.0 48.0 19.0 56.0 30.0 23.0 30.0 18.0 21.0
[601] 30.0 18.0 24.0 30.0 32.0 23.0 58.0 50.0 40.0 47.0 36.0 20.0 32.0 25.0 30.0
[616] 43.0 30.0 40.0 31.0 31.0 30.0 18.0 24.5 18.0 43.0 36.0 30.0 27.0 20.0 14.0
[631] 25.0 14.0 19.0 18.0 15.0 31.0 30.0 25.0 52.0 44.0 30.0 49.0 42.0 18.0 35.0
[646] 18.0 25.0 26.0 39.0 45.0 42.0 22.0 30.0 24.0 30.0 48.0 29.0 52.0 19.0 38.0
[661] 27.0 30.0 33.0 6.0 17.0 34.0 50.0 27.0 20.0 30.0 30.0 25.0 25.0 29.0 11.0
[676] 30.0 23.0 23.0 28.5 48.0 35.0 30.0 30.0 30.0 36.0 21.0 24.0 31.0 16.0 30.0
[691] 19.0 31.0 6.0 33.0 23.0 48.0 28.0 18.0 34.0 33.0 30.0 41.0 20.0 36.0 16.0
[706] 51.0 30.0 30.5 30.0 32.0 24.0 48.0 57.0 30.0 54.0 18.0 30.0 30.0 43.0 13.0
[721] 17.0 29.0 30.0 25.0 25.0 18.0 8.0 46.0 30.0 16.0 30.0 30.0 25.0 39.0 49.0
[736] 31.0 30.0 30.0 34.0 31.0 11.0 27.0 31.0 39.0 18.0 39.0 33.0 26.0 39.0 35.0
[751] 6.0 30.5 30.0 23.0 31.0 43.0 10.0 52.0 27.0 38.0 27.0 30.0 30.0 30.0 15.0
[766] 30.0 23.0 18.0 39.0 21.0 30.0 32.0 30.0 20.0 16.0 30.0 34.5 17.0 42.0 30.0
[781] 35.0 28.0 30.0 9.0 16.0 44.0 18.0 45.0 51.0 24.0 30.0 41.0 21.0 48.0 30.0
[796] 24.0 42.0 27.0 31.0 30.0 26.0 47.0 33.0 47.0 28.0 15.0 20.0 19.0 30.0 56.0
[811] 25.0 33.0 22.0 28.0 25.0 39.0 27.0 19.0 30.0 26.0 32.0# Nuevo diagrama de cajas y bigotes con la columna "Age" filtrada
boxplot(edad_sin_out, horizontal = TRUE, main = "Diagrama de Cajas - Edad Optimizada", xlab = "Edad")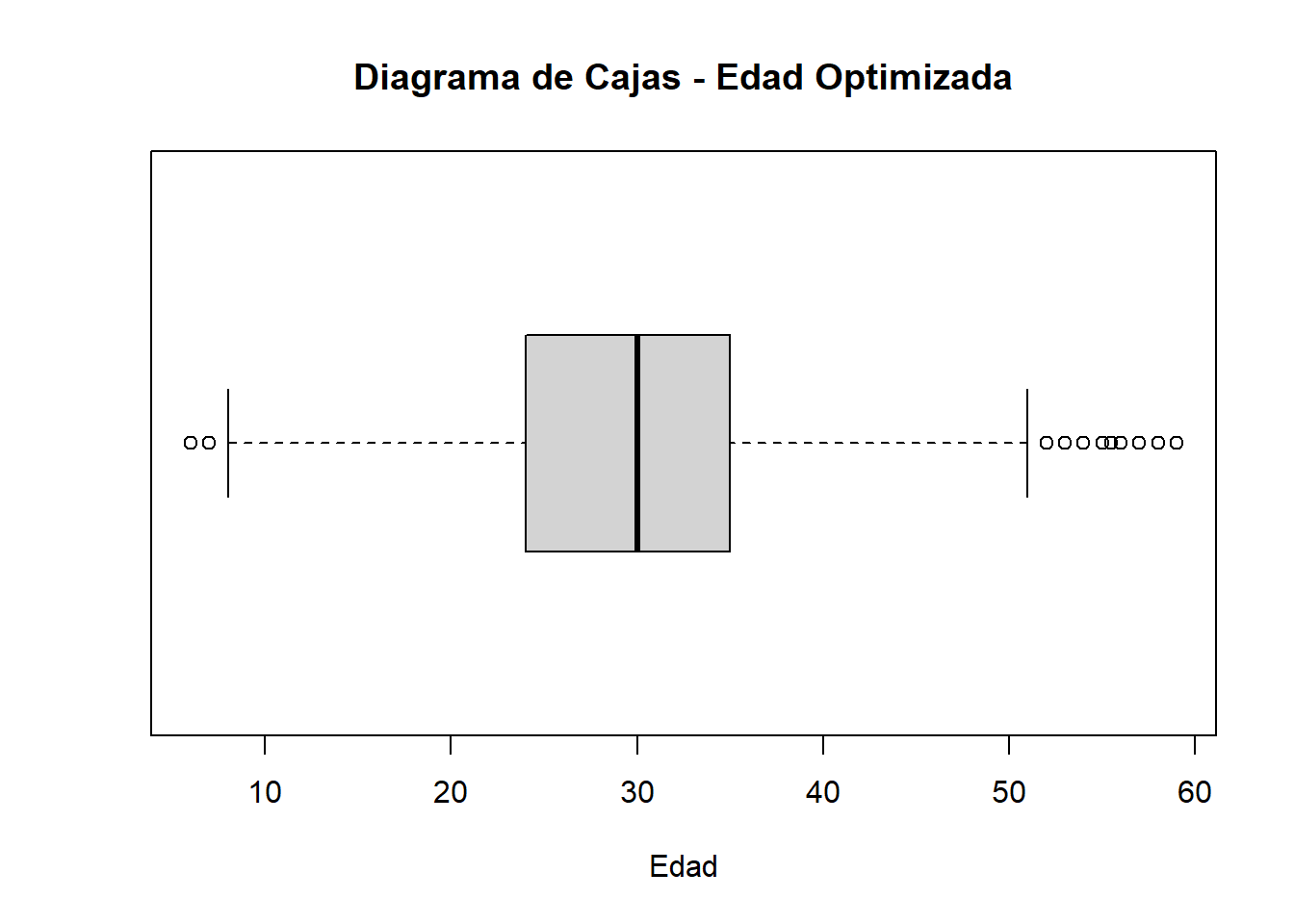
Data Tratada y lista para Analizar:
# Filtra las filas donde la edad es menor o igual a 5 o mayor o igual a 60
datos_filtrados <- datos[datos$Age <= 5 | datos$Age >= 60, ]
# Imprime las primeras filas del conjunto de datos después de la filtración
head(datos_filtrados) PassengerId Survived Pclass Name Sex
8 8 0 3 Palsson, Master. Gosta Leonard male
11 11 1 3 Sandstrom, Miss. Marguerite Rut female
17 17 0 3 Rice, Master. Eugene male
34 34 0 2 Wheadon, Mr. Edward H male
44 44 1 2 Laroche, Miss. Simonne Marie Anne Andree female
55 55 0 1 Ostby, Mr. Engelhart Cornelius male
Age SibSp Parch Ticket Fare Cabin Embarked
8 2 3 1 349909 21.0750 S
11 4 1 1 PP 9549 16.7000 G6 S
17 2 4 1 382652 29.1250 Q
34 66 0 0 C.A. 24579 10.5000 S
44 3 1 2 SC/Paris 2123 41.5792 C
55 65 0 1 113509 61.9792 B30 C